Modern IT companies that are developing in parallel a huge quantity of projects using different business-process models and development models. The most popular models are Scrum[1], Agile[2,3], Waterfall model[4].
Agile software development describes a set of principles for software development under which requirements and solutions evolve through the collaborative effort of self-organizing cross-functional teams.[1] It advocates adaptive planning, evolutionary development, early delivery, and continuous improvement, and it encourages rapid and flexible response to change. [3]
Scrum is an iterative and incremental agile software development framework for managing product development.[1][2] It defines "a flexible, holistic product development strategy where a development team works as a unit to reach a common goal",[3] challenges assumptions of the "traditional, sequential approach"[3] to product development, and enables teams to self-organize by encouraging physical co-location or close online collaboration of all team members, as well as daily face-to-face communication among all team members and disciplines involved. [4]
The waterfall model is a sequential (non-iterative) design process, used in software development processes, in which progress is seen as flowing steadily downwards (like a waterfall) through the phases of conception, initiation, analysis, design, construction, testing, production/implementation and maintenance. [5]
Not all companies cannot afford to develop using agile method because of different departments and project members are located in different locations (cities, countries). In this regard, one of the most important target in Project Management is to Save and to Improve project Teams.
The formation process of team that should be involved in multiprojects is iterative and envisaging possibility to redistribution of team members during projects lifecycle. Using an approach that take in account team members skills allows to determine precisely the levels of skills and experience of each team member. All existing methods take in account only the presence of skill, but not a skill level or experience with current skill.
The presence of any skill means possession of competence by the person on a basic level, that does not ensure the effectiveness of the specified indicators of functioning (quality of performance) of multiproject team.
Because in the project's boundaries the necessary degree of competence can be different, there is a need to develop effective methods for the formation of multiproject teams based on the level of competence (skills levels). In cases, when project team already been formed, some of team members could not have the necessary skill level, there are two ways to solve the problem: hiring a new specialist or advanced training of current specialist. In most cases hiring a new specialist need much more financial ant time recourses. In this case, it is more effective to develop the skills of current employees.
Having data of skills level of current team members, assessment of employees from managers, employees experience on current position, the manager can define which skill should be improved to face the target (project target or other) with minimal time and material costs.
That is why the task of classification based on known database is actual for now. There are a lot of methods of building classification rules – from heuristic rules of Top management, to using intellectual data analysis methods, like Decision trees, Bayesian rules, neural networks.
Main goal
The main goal of this work is to develop a recommendations of using a Bayesian method and building basing on it a Decision Tree to finding a Skills level of specialist and defining a specialist role in a project.
During the solution of the problem of forming of a project team in multiproject environment the following aspects should be considered:
- Hiring a new specialist and definition of his new the most appropriate role in company projects (multiproject environment)
- Rearrangement of current project team when team should be involved in a new project.
The main target of this work is to develop a recommendations of using a Bayesian method and building basing on it a Decision Tree to finding a Skills level of specialist and defining a specialist role in a project.
When there is a need to solve this problem of forming a new project team the main input data is Curriculum Vitae, that should be previously analyzed by Human Resources department and the CV’s should be formalized as a spreadsheet data. Also taken into consideration participation of candidate in previous completed projects, his involving in completed projects and his activities in completed projects. Based on all this data above, the top management should make a binary subjective decision, that specialist is “Good” or “Bad”.
In order to definition of possibility to add a specialist candidate to project team basing on information about project proposed to compose a test, which will consist of base directions of project requirements for candidates for participation in the project.
Let’s see on example of forming project team for project of reconstruction of responsive web-source, created on Drupal CMS. Project team consist of Graphic Designer, Front-end developer and back-end developer. As the first step let’s define a High-level project assumptions:
- To create new responsive UI there is no need to take in account specifics of Drupal CMS.
- To develop Responsive Front-End HTML code, we need a specialist, that have skills of responsive Cross-browser coding using modern technologies (HTML5, CSS3).
- To develop back-end of our web-source on CMS Drupal, we need a high skills specialist, that have success experience of developing projects such as current one. Because in current project we need to reconstruct existing web-source, this specialist should also have an experience of working with “unfamiliar” code.
As a result of analysis of project specification we can define a requirements system:
Graphic Designer
- Knowing Adobe Photoshop: yes/no
- Knowing the most popular screens resolutions for all modern devices: yes/no
- Experience of creating a mockups and graphics for cross-browse solutions (Desktop, mobile): yes/no
Front-end developer
- High experience in HTML5, CSS3, Bootstrap: yes/no
- Knowing PHP, JavaScript: yes/no
- Knowing Adobe Photoshop: yes/no
- Knowing MooTools, jQuery: yes/no
- Experience in front-end coding as “pixel-perfect” standard, cross-browse coding: yes/no
- Knowing English (reading documentation): yes/no
Back-end developer
- Work experience: number of years
- Web-sources development using Drupal CMS: yes/no
- Web-sources development using any other CMS: yes/no
- Good knowing PHP: yes/no
- Experience in working with MySQL Database: yes/no
- Knowing of JavaScript: yes/no
- Knowing English (reading documentation): yes/no
Assessment of competence based on fuzzy relationships
To provide an assessment of competence candidates should pass a tests. The answers on test questions should be formed as table (fuzzy relations).
The results of quiz of candidates provided in table 1.
Table 1. results of quiz
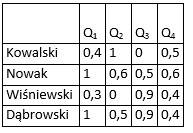
The relations between questions and verifying skills should be formed as table (Table 2) – the fuzzy relations, where:
- Q – questions that verify skill P
- S – skills
Table 2. Fuzzy relations table

On next step using max-min fuzzy relations, according to provided data about experience and subjective binary assessments let’s create an overall table with relations of Candidates and verifying skills (Table 3).
Table 3. General table – Fuzzy relations of verifying skills
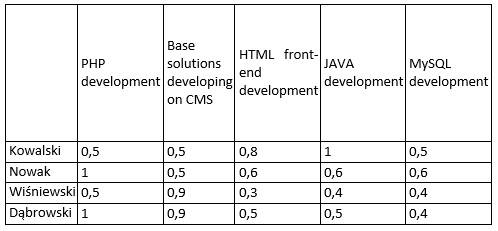 C=[For example, for candidate Kowalski the value 0,5 (PHP development) defines in the further way:
C=[For example, for candidate Kowalski the value 0,5 (PHP development) defines in the further way:
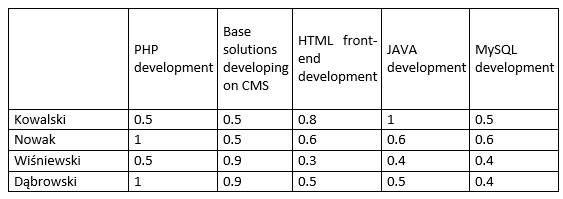
0.5 0.5 0.8 1 0.5
1 0.5 0.6 0.6 0.6
0.5 0.9 0.3 0.4 0.4
1 0.9 0.5 0.5 0.4
];
F=cell(4,1);
F={'Kowalski' 'Nowak' 'Wiśniewski' 'Dąbrowski'}';
t = classregtree(C,F,'names',{'PHP' 'CMS' 'HTML' 'JAVA' 'MySQL' },'minparent',1);
Table 4. Source data to building a decision tree
 The constructed Decision tree has the form
The constructed Decision tree has the form
Decision tree for regression
- if HTML<0.4 then node 2 elseif HTML>=0.4 then node 3 else Kowalski
- class = Wiśniewski
- if PHP<0.75 then node 4 elseif PHP>=0.75 then node 5 else Kowalski
- class = Kowalski
- if CMS<0.7 then node 6 elseif CMS>=0.7 then node 7 else Nowak
- class = Nowak
- class = Dąbrowski
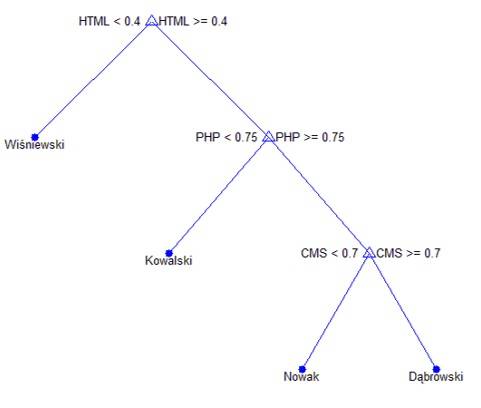
Figure 1. The Decision Tree
As a result of the analysis of the decision tree, is determined that in order to implement tasks only on CMS Drupal, we should hire Dąbrowski candidate, but if we need to implement any other front-end tasks without CMS, we should hire Nowak candidate.
Conclusion
This method allows you to give recommendations to Management of recruitment, which of the candidates will not immediately go to the vacant position, and which ones will do, but have the competence to be increased. Increasing the input data for this algorithm will improve the quality of recommendations.
Links and sources
Author: Oleksii Sokolov
Project Manager, Comarch Technologies